经过近两年来的不间断折腾,我手头的古董设备们基本可以愉快地联网”冲浪”了。但正如在《奇怪的需求2》文中介绍的,能联网能只是万里长征第一步——对于一台2000年代初的设备来说,浏览器只是它联网能力的一部分。在那个智能手机还没把人类彻底惯坏的年代,电子邮件、联系人、日历和待办事项的同步,才是PDA和早期笔记本的核心生产力功能。而这些功能,在2026年的今天,基本已经废了。
问题
过去几年的几篇年度捡垃圾报告已经介绍过我手头的各种古董设备,可以用于”生产力”的古董设备包括但不限于:ThinkPad X40(Windows XP+Outlook2007)、ThinkPad X20(Windows 2000 + Outlook 2003)等笔记本,以及一些可以使用ActiveSync同步的Windows CE/Mobile设备,如HP Jornada 688(Windows CE 2.11)、HP 112(Windows Mobile 6.0)等。
这里需要区分一下场景。移动设备(Windows CE/Windows Mobile)通过ActiveSync协议同步,到现在其实还能用,微软虽然早在2013年就放弃了对WM设备的支持,但ActiveSync本质上就是个PC程序,只要能启动同步就可用。真正的问题出在PC端的Outlook上——Outlook 2003到2010这些版本,当年设计的时候用的是基本认证(用户名+密码)来连接Exchange Server。而微软在2022年前后把Outlook.com的基本认证给废弃了,全面转向OAuth 2.0。这意味着你打开ThinkPad X40上的Outlook 2007,输入你的Outlook.com账户密码,它会告诉你:认证失败。
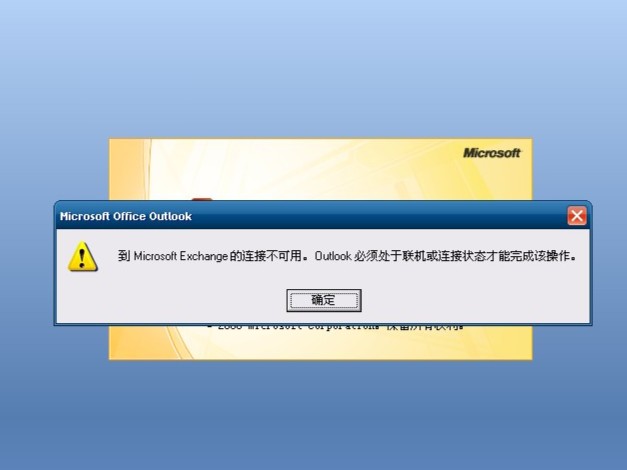
不是你的密码错了,是认证方式变了。就好比你拿着钥匙去开门,锁没换,但物业通知你以后只认指纹——你的钥匙再好使也没用。
有现成方案吗?
说实话,Retro Computing圈子里很少有人有这种需求。大多数人折腾古董设备是为了玩游戏、跑老软件、怀旧一把,没人会在意一台2003年的笔记本能不能收邮件和同步日历,大不了从现代设备上导出一份CSV再导入就完事了。
但我不一样,在这种问题上我有技术强迫症——
我想要的场景是这样的:我只维护一套邮件、联系人、日历和待办,但这套数据在我的手机、现代电脑上能正常同步使用的同时,古董设备们也能拿到同样的数据。打开ThinkPad X40上的Outlook 2007,看到的联系人和手机上的一样;在Jornada 688上翻日历,看到的日程和现代设备上的一模一样。
邮件还比较好处理,有IMAP4和POP3这两个万年不变的邮件传输协议托底,问题在于联系人、日历和待办。现代设备和Outlook.com之间通过Exchange协议直接同步,毫无问题。但古董设备的Outlook和Outlook.com之间?断联了。中间差一个桥。
有没有现成的方案,这是我的最开始的想法。我找了一圈,没人做这种东西。倒也不意外——谁会为一个可能全世界只有几十个人有需求的场景开发商业软件呢。没办法,自己动手吧。
为什么要让古董设备”活着”?
说到这里可能有人会问:折腾这些有什么意义?一台2003年的笔记本,同步不了就算了呗,用手机不就行了?
这个问题我被问过不止一次。要回答它,我们得先理清Retro Computing复古计算和老设备收藏的区别。
在我看来,Retro Computing不只是把旧设备点亮、跑个老游戏、拍张照发个朋友圈就完事了。这种叫老设备收藏,不叫Retro Computing。真正的Retro Computing,是让旧设备在今天的世界里依然能干活——能联网、能收邮件、能处理日程、能参与到你当下的数字生活中。不是把它供在柜子里当展品,而是让它坐在桌上当工具。
这件事之所以重要,是因为我们正在经历一场悄无声息的”数字退化”。在过去的N篇文章中,我曾无数次的阐述过一个一直以来的观点。2011年前后移动互联网的兴起,客观上降低了互联网的使用门槛,让原本不会用电脑的人也上了网。这当然是好事。但硬币的另一面是,它或多或少破坏了互联网本身的一些东西——纯粹感、开放感、以及那种”一个URL就是一切”的简单美学。
这个问题在中国尤其明显。PC互联网在中国实际上从来没有真正走进大众。当大多数人第一次触网的时候,面对的已经是微信和App Store了。对绝大多数的移动互联网原住民而言,互联网从一开始就不是浏览器和搜索引擎。这直接导致了一个结果:App生态对Web生态形成了绝对碾压。今天的国内互联网,本质上是一个个封闭的App孤岛,而不是一张开放的Web。你很难想象一个没有全功能微信的手机在中国能干什么(比如我曾使用了5年之久的Windows Phone和现在“遥遥领先”的原生Harmony OS)——但当我们让时光倒退30年,在PC互联网时代,一个浏览器就是整个世界。因此我对古董设备的定义也很简单,以2011年为界,之前的设备都能归纳进这个范畴。
从这个角度看,Retro Computing想传达的东西就清晰了:它是在复古过程中对简单的致敬。那个时代,一个浏览器、一个邮件客户端、一个日历,就构成了完整的数字生活。没有App孤岛,没有平台锁定,没有”请在微信中打开”。设备之间通过开放协议互联互通,你的数据属于你自己。
让古董设备在今天依然能参与这个体系,不是因为怀旧——好吧,也有一点怀旧——而是因为那个简单的、开放的、以协议而非平台为中心的数字世界,值得被记住,也值得被延续。
当然,以上都是我事后编的高大上理由。最开始的动机其实就是强迫症加装逼。在一个阳光明媚的午后,我坐在星巴克的咖啡桌旁。当别人拿着手机炫耀”看我这iPhone 17 Pro Max”,我掏出一台ThinkPad X40,打开Outlook 2007,收件箱里赫然躺着和他一模一样的最新邮件——绝对的小众,极致的简洁,纯粹的享受?(不是)
好吧,我承认,更现实的场景是:别人看到我在用一台2003年的笔记本收邮件,投来了关爱智障的眼神。但这不妨碍我觉得这件事很酷。毕竟在这个万物皆可云的年代,能用一台比很多人年纪还大的设备处理日常工作,本身就是一种行为艺术。而能让这种行为艺术真正”能用”而不只是”能开机”,大概就是我作为Retro Computing爱好者最后的倔强了。
思路:搭一座桥
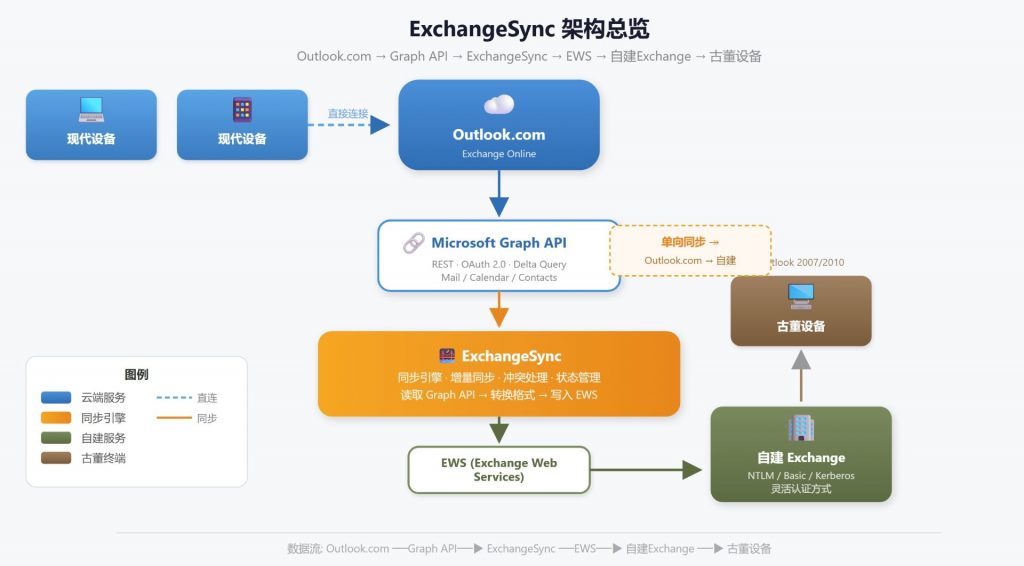
既然古董设备的Outlook连不上Outlook.com,但能连自建的Exchange Server(自建服务器想支持什么认证方式就支持什么),而Outlook.com的数据又可以通过Microsoft Graph API获取——那思路就很明确了,搭一座桥,把数据从云端搬到本地。
- 数据源:Outlook.com(通过Microsoft Graph API获取)
- 数据目标:自建的Exchange Server(通过EWS写入)
- 同步方向:Outlook.com → 自建Exchange,单向同步
这样,所有设备的数据来源都是Outlook.com。现代设备直接连Outlook.com,古董设备连自建Exchange Server,两边看到的是同一份数据,只是路径不同。这做桥用来同步联系人、日历和待办,邮件直接走IMAP4即可。
技术实现
技术栈
- 框架:Spring Boot 2
- 前端:Vue 3 + Element Plus
- 持久层:MyBatis 3.5.13 + SQLite
- 认证:Azure AD OAuth 2.0(Graph API端)+ 基本认证(EWS端)
- 核心依赖:Microsoft Graph SDK + EWS Java API 2.0
选Spring Boot是因为够成熟,生态完善,遇到问题好查。SQLite则是因为这东西本质上是个个人工具,用不着MySQL这种重量级选手,SQLite的单文件特性反而方便部署和备份。
同步流程
整个同步分三步走。
第一步:认证
需要完成两组认证。Graph API那边走Azure AD的设备代码流(Device Code Flow),用户在浏览器里输个代码就搞定授权。EWS那边简单粗暴,用户名+密码直接上,自建服务器嘛,认证策略自己说了算。
graphProperties = properties;
final String clientId = properties.getProperty("app.clientId");
final String tenantId = properties.getProperty("app.tenantId");
final String[] graphUserScopes = properties.getProperty("app.graphUserScopes").split(",");
deviceCodeCredential = new DeviceCodeCredentialBuilder()
.clientId(clientId)
.tenantId(tenantId)
.challengeConsumer(challenge)
.build();
userClient = new GraphServiceClient(deviceCodeCredential, graphUserScopes);
第二步:拉数据
通过Microsoft Graph API从Outlook.com把联系人、日历、待办拉下来,转成内部DTO存进SQLite。以联系人为例:
ContactCollectionResponse contacts = userClient.me().contacts().get(requestConfig ->{
requestConfig.queryParameters.top = 100;
});
List<ContactDto> contactDtoList = new ArrayList<>();
if (contacts != null){
for (Contact contact : contacts.getValue()){
ContactDto contactDto = processContact(contact, userClient);
contactDtoList.add(contactDto);
}
}
return contactDtoList;
第三步:写回去
把SQLite里的数据通过EWS写入自建Exchange Server。联系人和待办的同步相对直接:
Contact contact = new Contact(exchangeService);
processContact(contact, contactDto);
contact.save();
return contact.getId().getUniqueId();
日历稍微麻烦一些——Graph API和EWS对重复事件(Recurrence)的表示方式不一样,需要做模式映射。我专门写了个工厂类来处理这个转换:
RecurrencePatternFactory patternFactory = new RecurrencePatternFactory(); RecurrenceRangeFactory rangeFactory = new RecurrenceRangeFactory(); appointment.setRecurrence( patternFactory.createPattern(dto.getPattern()), rangeFactory.createRange(dto.getRange()) );
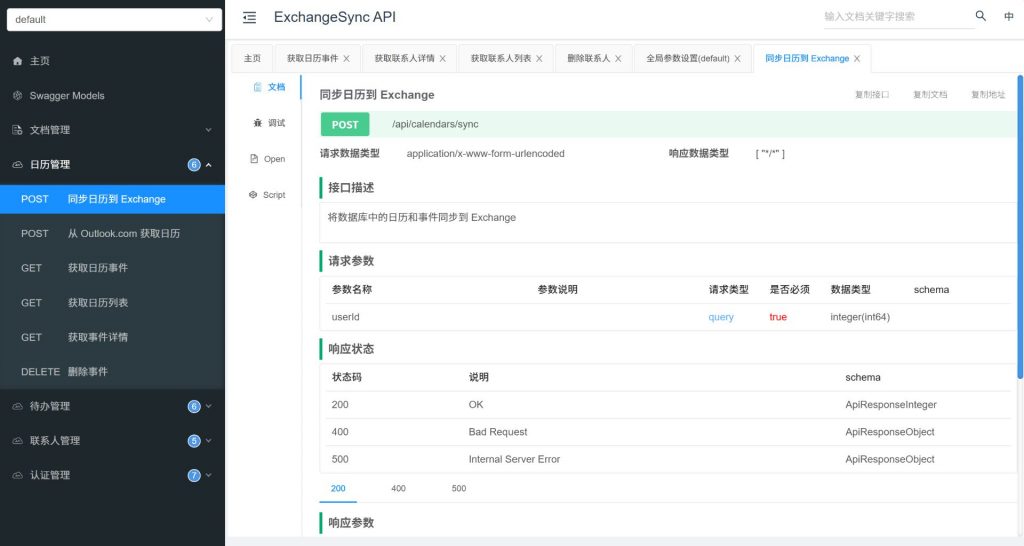
数据存储
数据库围绕三个核心业务设计:联系人、日历/事件、待办/任务。记录id和ews_id用于确定单一一条数据在Outlook.com和自建Exchange Server的唯一性并建立关联关系。用户认证信息(OAuth Token、EWS凭证)也存在SQLite里,敏感字段做了AES加密。Token刷新机制确保Graph API的访问权限不会因为过期而断掉。
-- Initialize SQLite database for ExchangeSync
-- Create calendar table
CREATE TABLE IF NOT EXISTS calendar (
id TEXT PRIMARY KEY,
name TEXT NOT NULL,
owner TEXT,
can_share BOOLEAN DEFAULT 0,
can_view_private_items BOOLEAN DEFAULT 0,
can_edit BOOLEAN DEFAULT 0,
change_key TEXT,
ews_id TEXT,
create_date DATETIME DEFAULT CURRENT_TIMESTAMP,
update_date DATETIME DEFAULT CURRENT_TIMESTAMP
);
-- Create task table
CREATE TABLE IF NOT EXISTS task (
id TEXT PRIMARY KEY,
todo_list_id TEXT NOT NULL,
ews_id TEXT,
title TEXT NOT NULL,
body TEXT,
importance TEXT,
status TEXT,
categories TEXT,
due_date DATETIME,
reminder_time DATETIME,
is_reminder_on BOOLEAN DEFAULT 0,
change_key TEXT,
create_date DATETIME DEFAULT CURRENT_TIMESTAMP,
update_date DATETIME DEFAULT CURRENT_TIMESTAMP,
FOREIGN KEY (todo_list_id) REFERENCES todo_list(id) ON DELETE CASCADE
);
-- Create contacts table
CREATE TABLE IF NOT EXISTS contacts (
id TEXT PRIMARY KEY,
displayName TEXT,
surName TEXT,
givenName TEXT,
emailAddress TEXT,
businessPhone TEXT,
homePhone TEXT,
mobilePhone TEXT,
jobTile TEXT,
companyName TEXT,
department TEXT,
birthday DATE,
homeAddress TEXT,
businessAddress TEXT,
create_date DATETIME DEFAULT CURRENT_TIMESTAMP,
update_date DATETIME DEFAULT CURRENT_TIMESTAMP,
changeKey TEXT,
photoFileName TEXT,
ewsid TEXT
);
Vibe Coding初体验
这个项目基本用QwenCode + Qwen 3.5 + Mimo 2.0 Pro完成。说白了,我当产品经理,AI当程序员。
听起来很美对吧?确实很美。你把需求说清楚,架构设计好,AI就能给你吐出一套能跑的代码。Spring Boot的Controller、Service、Mapper一层层安排得明明白白,Graph API和EWS的调用代码信手拈来,DTO转换逻辑也能处理得八九不离十。一个涉及两种不同API协议、多种数据同步模式、多用户认证体系的Spring Boot项目,从零到可用版本大概花了一周——搁以前纯手撸,光EWS的API文档可能就让我放弃了这个想法。
在两年多前我写那个EXIF标签批量修改器的时候(见《奇怪的需求1》),我还需要和ChatGPT逐个功能交互,一点一点把代码拷贝到IDE中。而如今,QwenCode CLI基本已经实现了从需求到运行的端到端处理,我所需要做的只是自然语言交互和一份详尽的Spec。AI的飞速发展不言而喻。
当然,AI程序员和人类程序员一样同样存在问题。比如EWS Java API的Maven依赖。这个库的依赖树堪称考古现场,各种历史遗留包互相打架。AI信心满满给我生成了一套pom.xml,编译的时候报错报得像过年放鞭炮。它把三个互相冲突的版本写进去了。最后还是我手动指定了单一版本才解决。
再比如日历的重复事件。Graph API和EWS对”每周一上午10点开会”这件事的表示方式完全不同,AI一开始试图用简单的字段映射糊弄过去。我一看输出的日历——”每周一”变成了”只发生一次”。后来我介入,强制要求AI改用工厂模式分别处理Pattern和Range才搞定。
总结一下:AI是一个非常高效的”高级程序员”,你把架构设计好、关键逻辑想清楚,它能帮你快速实现。但你要是完全放手不管,它能给你跑出一堆”看起来对但实际有坑”的代码。所以我的工作模式是——我当架构师+Code Reviewer,AI当程序员。人机结对编程,配合得还不错。
当然,必须要承认AI单纯作为程序员的能力远胜于我。这个项目的前端也是AI一手包办的。我是一个纯后端选手,前端技术栈基本停留在”jQuery+会用F12″的水平。Vue是什么?Element Plus能吃吗?完全不懂。但AI懂。我只需要告诉它”我要一个能管理联系人、日历、待办的界面,请根据API构建一个前端页面,同时支持EWS和Graph API登录”,它就给我攒出了一套完整的Vue 3 + Element Plus前端。登录页、数据列表、同步操作按钮,一应俱全。我甚至都没看过前端的代码——反正我也看不懂,能用就行。(不是好的工程实践,但对个人项目来说够了)
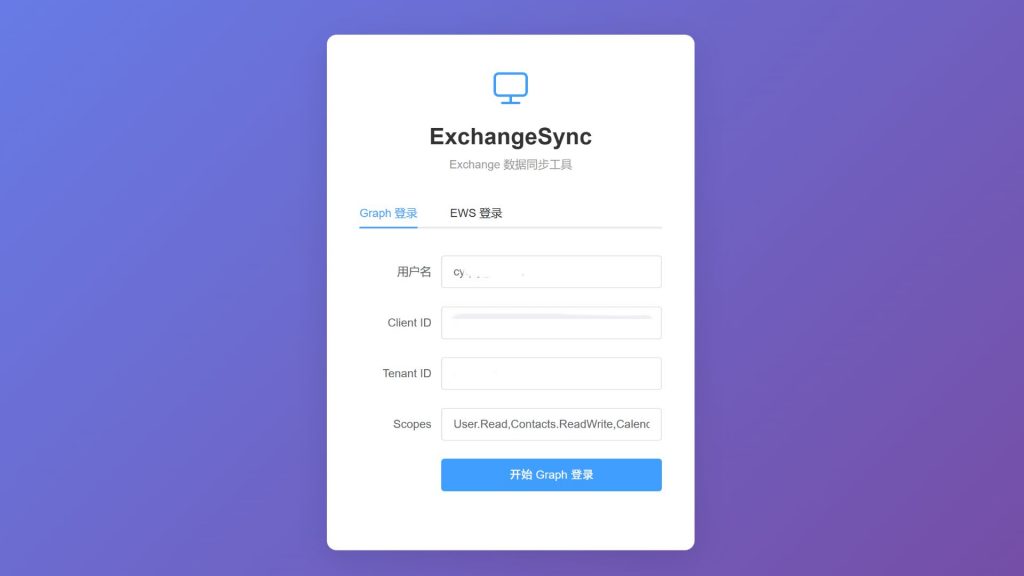
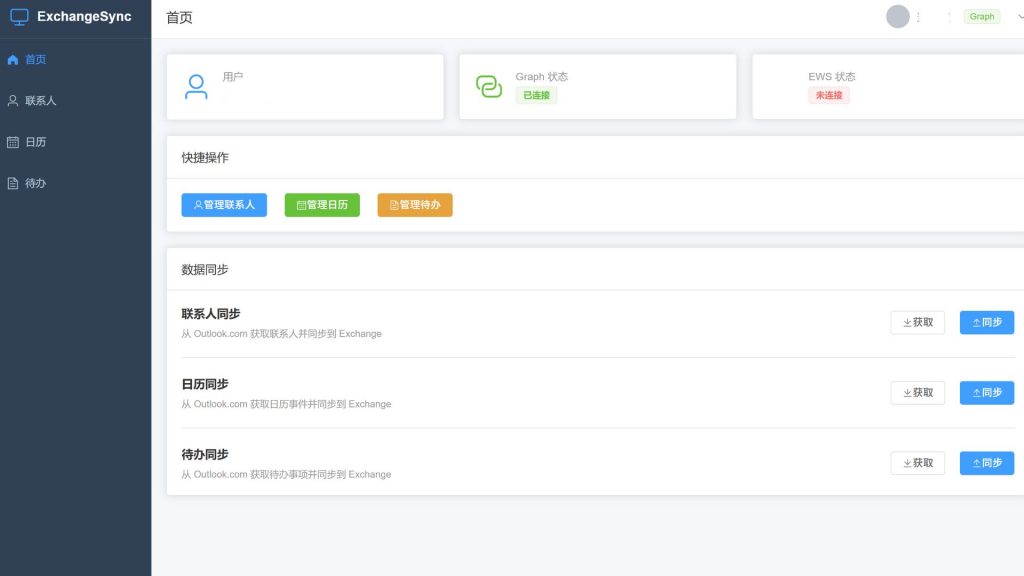
古董设备 × 现代AI
说实话,这个项目最让我觉得魔幻的地方,是它的开发方式本身。
项目的开发机是一台32G内存的Surface Pro 11,调用着时下最时兴的Token Plan承载的云端的大语言模型,通过自然语言对话的方式,写出了一个Spring Boot项目。而这个项目的唯一目的,是让一台2003年的ThinkPad X40能同步联系人、日历和待办。
2003年的技术和2026年的技术,在这个项目里完成了某种奇妙的握手。一边是Exhange Server 2010古早的基于WebService的EWS协议、基本认证、XP时代的软件生态;另一边是Microsoft Graph API的现代RESTful接口、OAuth 2.0认证、AI辅助编程。中间由我——一个同时拥有这两边情怀的人——把它们粘在一起。
某种意义上,这大概就是Retro Computing爱好者最终极的浪漫:用最先进的工具,服务于最古老的需求(自恋一下)。
效果
完成后的ExchangeSync提供了一套完整的RESTful API,覆盖认证、联系人、日历、待办的全生命周期管理:
| 模块 | 功能 |
| 认证 | Graph API设备代码流登录、EWS登录、状态查询、登出 |
| 联系人 | 从Outlook.com拉取、同步至Exchange、列表查询、详情查看、删除 |
| 日历 | 日历列表拉取、事件拉取、事件同步、事件详情、删除 |
| 待办 | 待办列表拉取、任务拉取、任务同步、任务详情、删除 |
现在,Outlook.com账户里的邮件、联系人、日历和待办,会自动同步到自建的Exchange Server上。手机和现代电脑继续直接用Outlook.com,古董设备们连自建Exchange——两边看到的是同一份数据。打开ThinkPad X40上的Outlook 2007,联系人和手机上的一样;在Jornada 688上翻日历,日程安排和现代设备上一模一样。

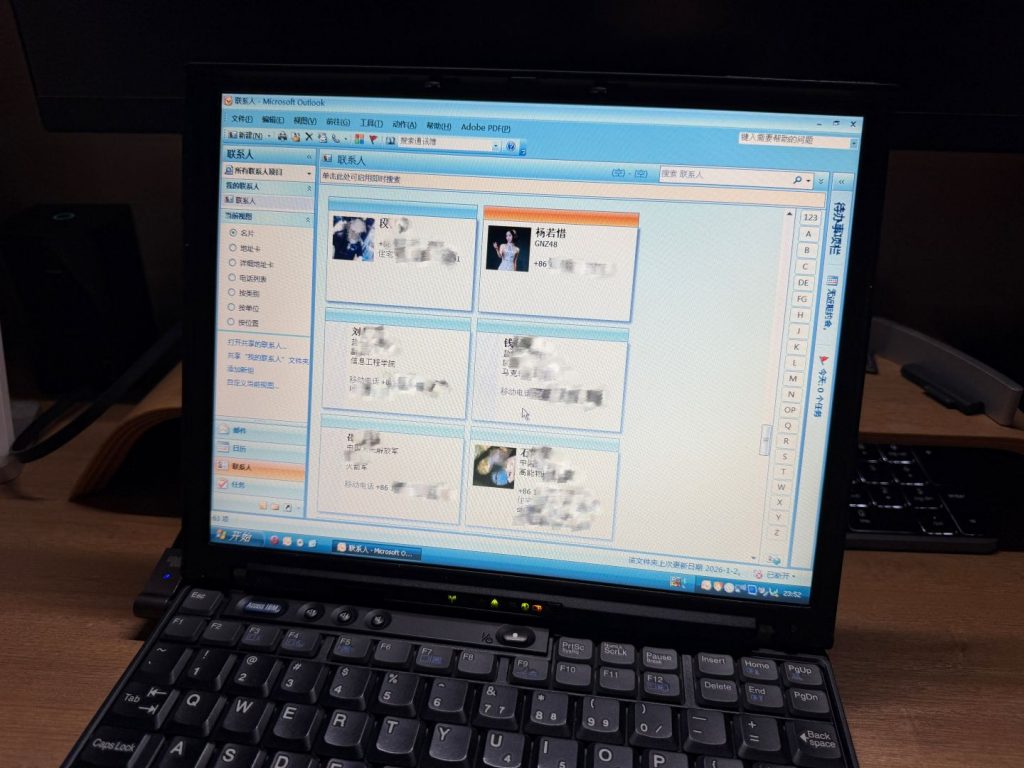
只维护一套数据,所有设备共享。技术强迫症,治好了。
项目信息
相关代码已开源:https://github.com/j-10cc/ExchangeSync
技术栈:Spring Boot/ MyBatis / SQLite / Microsoft Graph API / EWS Java API 2.0
欢迎关注。后续计划包括Token自动刷新的完善、前端界面的完善,以及更多同步策略(如双向同步)的探索。
后记
这篇博客本身也是AI写的。准确的说,是我用OpenClaw连接了雷军送的7亿Token Plan,喂了它我之前博客的风格参考,让它照着我的口吻把这篇文章攒了出来。你正在看的这些字,大概有80%是AI生成的,剩下20%是我修改的——包括这句。
所以你看,这个项目从代码到文档,AI的渗透率已经接近100%了。我干了啥呢?我提供了:强迫症、古董设备和审美。剩下的全是AI的活儿。这大概就是2026年程序员的日常——你负责有品味,AI负责干活。
最近总有人问我:AI都能写代码了,你这程序员是不是快失业了?
我的回答是:你看看这个项目,AI写的代码占了90%以上,但这个项目存在本身,AI想不出来。AI能做的事情很明确——你告诉它”用Graph API从Outlook.com拉联系人,通过EWS写入自建Exchange”,它能给你写出一套漂亮的代码。但它不会在某个凌晨三点突然灵光一现:”嘿,我应该让一台2003年的ThinkPad能同步Outlook.com的一切!”它没有这个需求,没有这个审美,也没有这种强迫症。
AI决定怎么做。人决定做什么。
这听起来像废话,但我觉得它精确地描述了AI时代人和AI的分工。你得知道什么是Graph API、什么是EWS、什么是OAuth,才能设计出这个桥。你得知道古董设备的Outlook为什么不兼容,才能定义出这个需求。你得在AI写出”能跑但有坑”的代码时,一眼看出哪里有坑。我在工作中曾反复和小组成员强调,我们需要有产品思维,需要成为有强技术背景的产品经理——懂技术,知道什么能做什么不能做,能把一个模糊的”我想要XXX”变成AI可以执行的Prompt,准确的约束Spec并且知道AI的能力边界。这种人在AI时代不是被淘汰的,恰恰是被放大的。
所以至少在当下,我的焦虑感暂时还没被AI放大。AI让我的效率翻了好几倍,但它替代不了我的强迫症和审美。这两样东西,大概是人类最后的护城河了。
当然,审美的活儿绝不轻松。AI第一版写出来的文章,怎么说呢,像一个刚毕业的计算机系学生写的——技术上没毛病,但读起来总有一种”助教批改作业”的感觉。经过好几轮的调整才变成了你现在看到的样子。所以你看,AI替代人类这件事,至少在”写出让人类愿意读的文字”这个领域,还有很长的路要走。
不过话说回来,如果AI哪天真能写出和我一模一样的文风,那我可能真的要考虑退休了。(笑)
——等等,我才33,连程序员35岁门槛都没到,你凭什么让我退休?你看,这就是人类之所以为人的地方。AI写的文章再好,最终也要人类来发。